Case Studies
How Long Does SEO Take to…
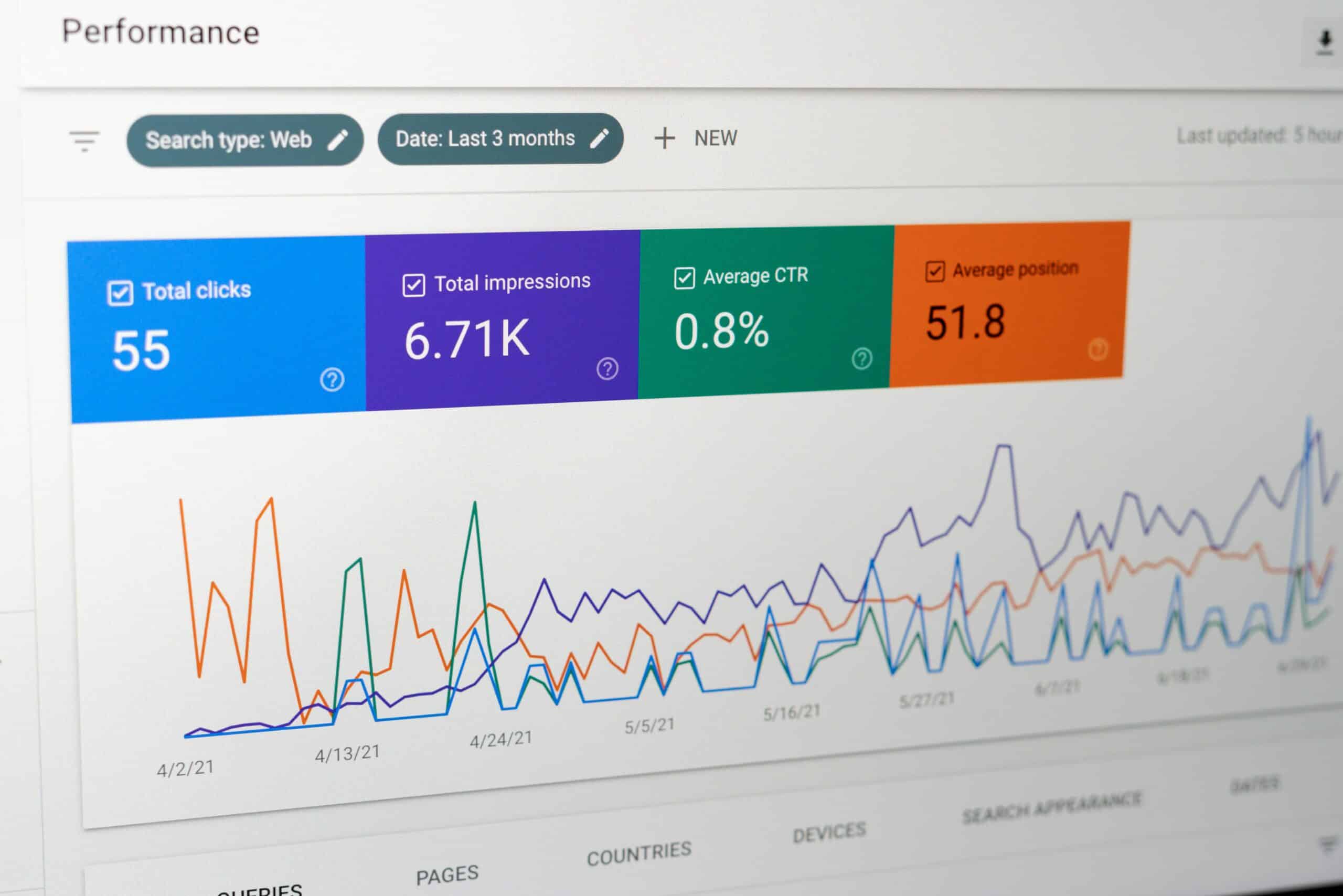
Wondering how long does take SEO to have an impact? With many conflicting answers out there, we give you all the data, so you know what to expect (and when)
Wondering how long does take SEO to have an impact? With many conflicting answers out there, we give you all the data, so you know what to expect (and when)

Ever considered running an internal SEO clinic for various stakeholders? While SEO is its own discipline, in almost all in-house

Site speed, PageSpeed, Core Web Vitals (CWV) or whatever you want to call it: improving the speed of websites has for a number of years been one of the most powerful tools at my disposal in working on large scale websites.

Moobs, YOLO, slacktivist, clickbait. These words all turned up in the Oxford English Dictionary in 2016, signalling, perhaps, that the

Ever wondered why you should invest in branding? We’ll tell you all in this guide. Just give it a read and take notes.

Wondering whether Content Marketing can do anything for your business (big or small), read on because we’ve got all the answers you’re looking for. Here you’ll learn how it can help you achieve your goals.

If you’re considering hiring writers (freelance or in-house) for your team, read on. We’re going to tell you how we find the best ones and keep them engaged. Trust me, I’ve got heaps of experience.

Back in 2010 I had 0 clue about SEO. Like, seriously no clue. I don’t think I’d even heard the