Site speed, PageSpeed, Core Web Vitals (CWV) or whatever you want to call it: improving the speed of websites has for a number of years been one of the most powerful tools at my disposal in working on large-scale websites. Despite that, since Google first started their mission to get us to speed up our sites, a vocal minority of industry SEOs have debated its value.
Critically, these are often the same talking heads, who argue that crawl budget is irrelevant – and that’s the clue: these two concepts are inextricably linked – for the benefit of Google.
As an aside, for more than a decade, I’ve approached technical SEO with the overarching thought that technical SEO most often boils down to making your site easy to crawl, render and parse for GoogleBot – this is no different.
There’s an often quoted ‘study’ by Backlinko & aHrefs where they state: “We found no correlation between page loading speed (as measured by Alexa) and first page Google rankings.”, which while two years old, was no less incorrect then, as it is now.
So what’s the confusion?
It’s true to say that if you look at any large set of top 20 keyword rankings, and then extract the CWV score, you’re not going to make much of a positive correlation between higher rank and improved speed.
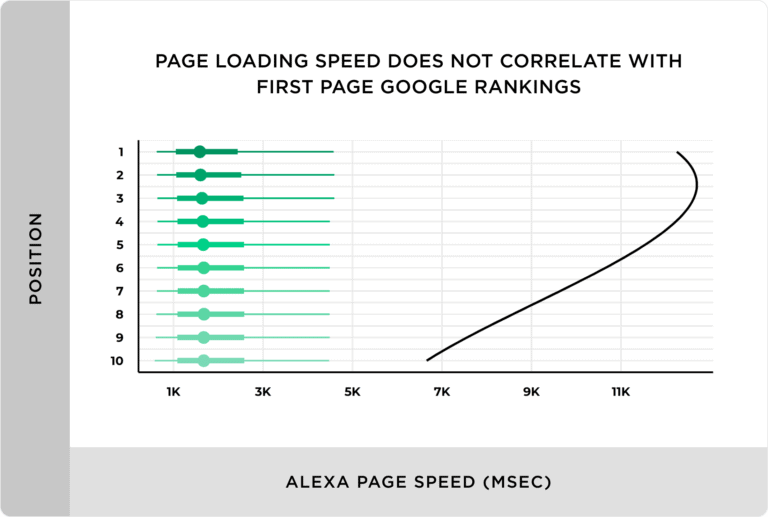
This analysis falls down, however, because the relevancy of the search result to the query is logically far more critical than the speed with which a page loads. If all other factors were identical (an unlikely/impossible scenario) then the speed may well be used as a tie-breaker but that’s an academic point at best.
The Intersection between Crawl Budget & Site Speed:
If there’s an SEO topic that’s less understood than speed, it’s crawl budget. A common misconception here is that this magical thing, crawl budget, is the SITE budget. It’s not really. The way I prefer to conceptualize this has always been to imagine it as Google’s overall crawl capacity, and how much share of that they are willing to invest in your site.
Imagine a scenario where you have a site with hundreds of millions of pages, all automatically generated with scripted text, a few variables, and trying to look like ‘good SEO content’ – you know the type, every large website out there (pretty much) has leveraged this approach at some point, I’ve even given conference talks on producing it scalably. You then have some links pointing at that website, Google finds it and starts crawling…
… Is it reasonable to assume that any search engine would, or should, make the investment to crawl hundreds of millions of pages. That they can programmatically see very quickly, are all effectively duplicate and offer very little unique value on their own individual page merits? No. They will only crawl a certain amount of them, realize the ROI in content they get from their crawl investment, and just go crawl elsewhere.
… Is it reasonable to also assume that a search engine would endure 10-, 20-, even 30-second page loads to access content on your site, when they can crawl any number of other websites in fractions of the time, to achieve the same level of net-improvement to their index? No. They will crawl a certain amount of them, and justifiably determine they can get more content, quicker, on other sites and just go crawl elsewhere.
Crawling those millions (or even hundreds of millions) of pages is a significant resource overhead. Rendering them takes processor cycles. Maintaining them in the index takes storage. Refreshing them takes more crawl resources, and so on.
How do I know if this affects me?
Simple: Google have a handy GSC drilldown under Pages > Page Indexing > Discovered – currently not indexed.

If in this report you see the line “Discovered – currently not indexed” you have pages that Google have decided not to bother crawling – this could be either crawl budget, or possibly a determination that the content itself is rubbish. The good news is both are fixable.
(The other line, Crawled – currently not indexed, means Google DID crawl it, but they still didn’t think it was worth indexing. That’s about as close to a sick burn that GSC gets).
The headline says “<10% of Sites”, why?
In a recent Google Webmaster Central podcast, featuring Martin Splitt, he said (and I’m paraphrasing here) “Everyone complains about crawl budget, but the reality is less than 10% of sites face this as an issue“. If your search console has the ‘Discovered – currently not indexed’ line, then it probably affects you…
How will improving Site Speed benefit Crawl Budget?
Quite simply: Google decides how much ‘effort’ to put into crawling your site. Let’s just simplify things and use time as the only resource. If it takes 10 seconds to load a page, and you improve that to 5 seconds, they can crawl 2x more pages with the same amount of budget expenditure. This is probably a huge oversimplification, and I’m sure an elf on the webmaster team could correct me in 10,000 words or more, but for the sake of this post, it’ll do.
As we know, in order for any page to receive traffic it has to be crawled, rendered, and indexed. You’ve just doubled the top of that funnel – doubling the potential set of pages that are even eligible to receive search traffic.
So it doesn’t increase the ‘budget’ instead, it allows you to squeeze more content into the allotted resource you had in the first place, ultimately resulting in (potentially) significant traffic improvement.
What if it doesn’t yield more indexed pages?
Then two things are likely. Firstly Google never wanted to index your content in the first place, so from an SEO perspective you probably want to take care of that. But you also significantly improved the user experience on your site, resulting in more time on site, more pages per session, more repeat visits and so on.
Basically, this is a good thing to do, regardless of the ultimate organic search performance outcome.
How can I tell if it’s worked? What specific factors are most important?
I don’t have numbers on the direct correlation between TTFB, FCP, LCP etc. vs. crawl budget (possibly that Google elf can help here) BUT, what I can point out is the direct correlation between TTFB and pages crawled per day that you can see yourself, under Settings > Crawl Stats in GSC. Here’s a great example:

On the day where it spiked from 250ms up to 1.7s, the crawled pages dropped from about 2,000,000 average daily, down to 490,000. A greater than 75% drop. If there were only two metrics I could focus on for crawl budget, therefore, it would be TTFB (sub 300ms target) to allow Google to efficiently crawl, and a low LCP (sub 4s target as these are thresholds dictated by CWV) to allow Google to efficiently render.
To sum up:
The faster your site, the more pages you can get crawled.
The more pages are crawled, the more can be indexed.
The more indexed, the more chances you have to rank.
The more you rank, the more opportunity you have to receive traffic.
Even if you don’t see an indexing benefit, your users will love you more, and you’ll improve all sorts of user metrics to boot!
Have you had experience solving Crawl Budget issues? Anything you’d like to add for the community? Leave a comment below – Thanks!