Yesterday, SEMrush released an updated version of their June 2017 ranking factors report, again placing Direct Traffic right at the top of the list – stating that its the most important ranking factor for Google.
You can (and should) download it here.

For those that may not be familiar with SEMrush, they provide an excellent online set of tools for both SEO market analysis and site specific crawling, reporting, and a fairly extensive keyword list with plenty of data.
I’m a big fan of theirs (despite not having used the tool for a number of years) and they consistently won “Best Tool” in my old industry reports.
They also fairly consistently win Best Tool in SEO awards ceremonies etc. Basically, they can be considered an authoritative source of SEO analysis.
Some Definitions to ensure we’re in alignment:
Ranking Factor: One of the considerations Google makes when deciding how to appropriately rank a page for a given search query.
To qualify as a ranking factor, the item in consideration must drive in some way the relevance of the page to the query, or the strength of the page itself, and not be merely correlative or coincidental.
Other good examples of ranking factor studies have been published by Backlinko, SearchMetrics, SISTRIX and many others.
Direct Traffic: Requests that your website receives from browsers without an http_referrer.
This could be direct type in traffic, or bookmarked URLs.
It could also be website referral traffic that has lost its referrer (for instance on https>http links), URL shorteners that haven’t passed a referrer ID, particularly when links are clicked through from a non-web browser app, like Tweetdeck…
Finally, increasingly I see Google stripping the http_referrer itself from organic traffic. That last one happens a lot more than most people realize, and the total % has been increasing month on month for some years now.
Let’s Assume Direct Traffic IS a Ranking Factor:
While I’m initially skeptical of the claim, it seems a whole lot of other SEO’s think that direct traffic may indeed be a ranking factor:
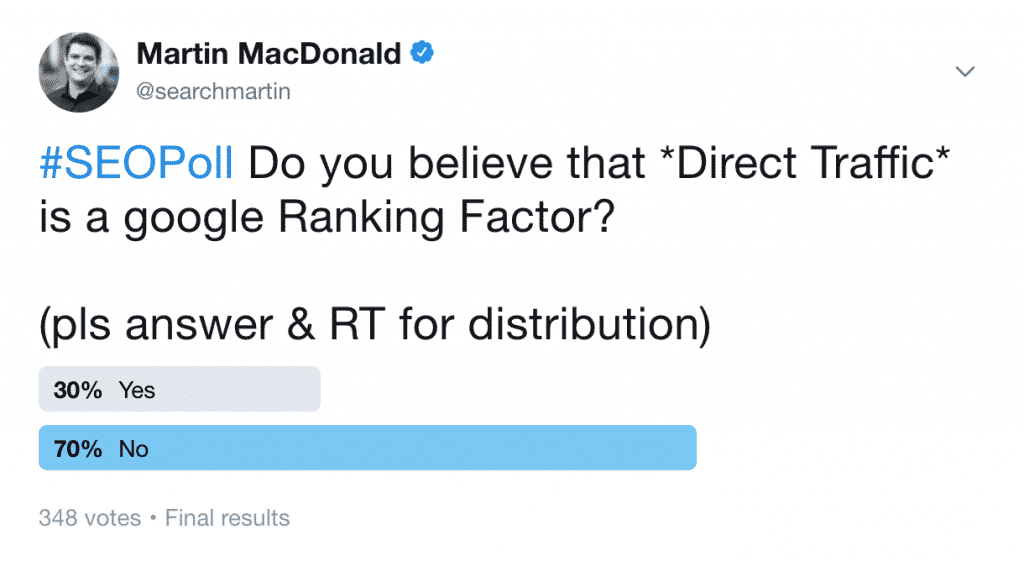
So lets think this through for a minute:
Q: Would Direct Traffic be a Good Quality Signal?
A: Sure, why not…. I guess sites that have a significant amount of direct type in traffic could be considered authoritative.
After all, if people are going straight to the site either by typing the URL in, or by bookmarking it, you could certainly ascertain that its serving a purpose, or is of high quality.
I certainly agree that this (direct type in traffic) might be valuable data for Google.

Q: Are Google Able to Get a Clean, Dependable Signal of ‘referrerless’ web traffic?
A: Also probably yes on this one.
They don’t need to rely on Google Analytics data either, since they both power a significant DNS service, are a large scale bandwidth provider through Google Fiber, have significant clickstream data through Google Chrome & other potential channels.
So, yes – I think they probably could get a decent sense of the number of requests without a referrer…
Although, thats no guarantee its actual type in traffic(!).
Q: Could Google Efficiently Parse this Data for Ranking Purposes?
A: I don’t see why not – once you can verify that there is direct traffic to a given URL, or root domain, you could apply it a score which updates periodically and is built into the overall site trust factor score. Also a pass in my mind.
So Why the Skepticism Then?
 I’ve got a couple of reasons, that in my mind are deal breakers…
I’ve got a couple of reasons, that in my mind are deal breakers…
1) The technical definition of direct traffic simply being requests made without an http_referrer is far too vague a concept.
We’re not talking about direct type in traffic most of the time, rather:
- requests made from non web browsers
- many URL shorteners
- social media platforms and apps
- links with mismatched security protocols
- links shared across devices (desktop to mobile particularly)
This varied source of “direct traffic” invalidates the theory that direct type in is a dependable quality metric – while it may be one, extracting the actual direct type in or bookmarked traffic away from the other sources is not currently possible.
2) As a ranking factor, it would be exceptionally easy to game.
If all you need to do is strip out the referrer on all internal links to “fool” google into thinking its direct traffic, you could do this with a few lines of PHP code, or with server configuration, and lets not forget that HTML5 actually gives us the option to prevent referrers from being passed with the a rel=noreferrer tag.
3) The industry wide migration to HTTPS:
Given that by design, HTTPS secure pages do not pass a referrer to http pages on requests, it effectively blacks-out huge portions of the linking web.
That from a server standpoint would make much of this traffic appear to be direct, unless specific steps are taken to re-insert referrer data.
Why Do SEMrush Think it IS a Ranking Factor?
My best guess is that, with the high number of factors Google is considering these days (some say 200+, others say thousands – I’m not making an estimate personally, but its certainly more than the ones they go into in their report) direct correlation between any of them can be remarkably low.
We see this time and time again in everyone else’s ranking correlation studies – links by themselves are an obvious indicator of page strength, but this is only considered hand in hand with Google’s perceived relevancy of the content of a landing page, vs. the query the user made.
That’s to say that, a page with high relevancy to the query, can outrank one with lower relevancy even though it has a much greater number of inbound links, and the perceived authority (PageRank) of those links.
Once you start mixing in post processing factors following document retrieval (ie. user behavior, bounce rate vs SERP competitors, time on site, site speed, page weight, etc. etc. etc.) the picture gets very murky indeed.
I can totally see why “direct traffic” correlates highly with rankings, its because by design Google is sorting better results, and better websites, higher in their results.
These websites are likely to correlate with having higher traffic, and in turn will generate higher numbers of “direct hits” (without a referrer). It all fits together forming a complex, but predictable picture.
Another significant point here is the continued obfuscation of SEO traffic as direct, by Google themselves. Famously Groupon conducted an “experiment” (or total mess up, depending on who you ask) which demonstrated that a significant amount of their direct traffic was in fact, organic.

I’ve seen this time and time again, particularly on long tail queries to deep pages on massive sites. When you de-index those pages from Google, they cease to receive direct traffic – two things that should not correlate.
You may have your own opinions as to why this may be the case, but I don’t think its too far a stretch to imagine that slowly migrating organic traffic into direct for analytics purposes, causes SEO’s harm, by devaluing their work.
But maybe thats just me.
The True Test of an Algorithm
The best test of an algorithm, isn’t whether it can explain results, rather whether it can predict them.
This wouldn’t be too hard to test in the context of what we’re discussing here – all a large site would need to do would be to mask internal referrers at a server level, to make it appear that 100% of traffic navigating internally was in fact direct traffic.
If the theory put forward by SEMrush were true, that direct traffic is a ranking factor, then you would theoretically see rankings explode – if it were the single most important factor.
I’m not going to suggest to any of my clients that they do this, but you could theoretically build a fairly robust test.
Or, you know, just buy lots of traffic and point it through a redirector to strip the referrer….
…I’m sure that will appear on Fiverr some point in the next couple of weeks if SEMrush continue to push this theory forward 😉
All this is Just My Opinion Though: What Do You Think?
As it appears, around a third of SEO’s believe it is a ranking factor, I’d LOVE to have your comments below – don’t be shy! 😉