[aesop_parallax img=”https://webmarketingschool.com/wp-content/uploads/2015/07/shutterstock_176194913.jpg” parallaxbg=”on” captionposition=”bottom-left” lightbox=”on” floater=”on” floaterposition=”left” floaterdirection=”up”]
A small thread yesterday on HackerNews claimed that Twitter had de-indexed their entire site, using Robots.txt to block crawler access.
They link to the file http://www.twitter.com/robots.txt which appears as below:

OK that looks like they are de-indexing the site?
As you can perfectly well see, they ARE disallowing robots from crawling www.twitter.com, but that is absolutely by design and not by accident.
If you check the robots.txt file for the ROOT domain, you’ll see it is quite a bit more in depth:
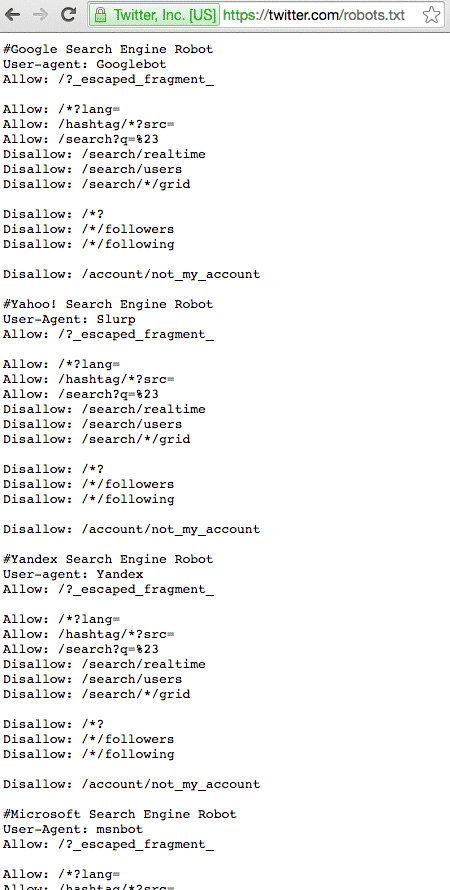
So why the Difference?
Its actually really simple, one of the basic elements of SEO is preventing duplicate content. Typically SEO’s recommend only having one version of your site, either on www.yoursite.com or just yoursite.com, but NOT both.
Twitter have decided to go the route of preventing indexation by way of preventing crawling of the www. subdomain, rather than rewriting their URLs to not include them, while redirecting the traffic.
You can see their indexation not including www.twitter here:
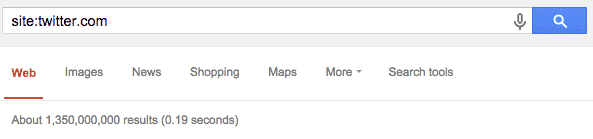
vs. the indexation for the www.twitter subdomain specifically:
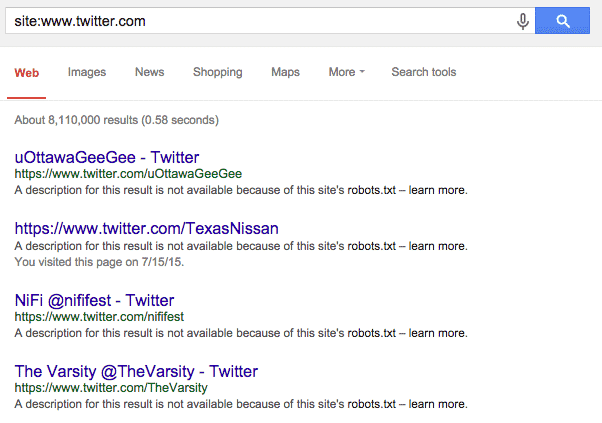
Notice the two differences:
Firstly, there are 1.3 billion pages in the index for the primary domain, and just 8 million for the incorrect version with “www”.
Secondly, each of the results in the second version dont have a meta description, thats because Google can not crawl the pages, so doesnt know how to describe them.
Then why are they in the index?
There’s a pretty simple explanation for that as well, other web pages link to twitter accounts, often incorrectly, INCLUDING the www. in the URL.
That’s why Google knows about the page, so it appears in a Site: search, but its not in the index, nor do they have a description for it.
So can we stop losing our Minds?
Please.

{kind=link}