Negative SEO has been a hot topic for a number of years now, and we all know the typical routes to demoting your competition:
1) buy loads of crappy links (ie. xrumer/fiverr blasts)
2) duplicate the target site across hundreds of other domains, (squidoo lenses for instance)
3) breach GWMT security and de-index
4) manipulate mass spam annotations (email/DMCA’s/spamhaus etc)
5) link takedowns (send email to people linking to a competitor, and ask/threaten them to remove them)
Any of those might work, but none are particularly reliable.
Most actually stand a good chance of positively influencing their results instead.
Crucially, its not hard to notice this stuff going on, as long as you know where/how to look.
A savvy SEO would probably take another route.*

(*by recruiting Pandas & Penguins, and directing
them towards problems you can create).
If I were going to look for SEO vulnerabilities, I would be more inclined to just carry out a full SEO audit on a competitors website and look for weak spots, then try and optimise their weakness.
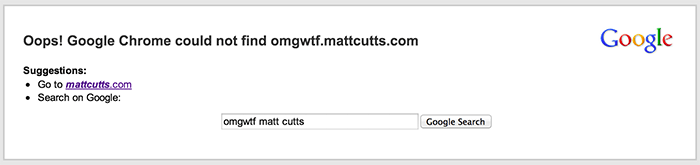
Example: MattCutts.com
Lets just say I have a site that I wanted to rank for the term, “iPhone User Agent“.
While doing some competitive research, I stumble on the domain mattcutts.com which ranks 4th:
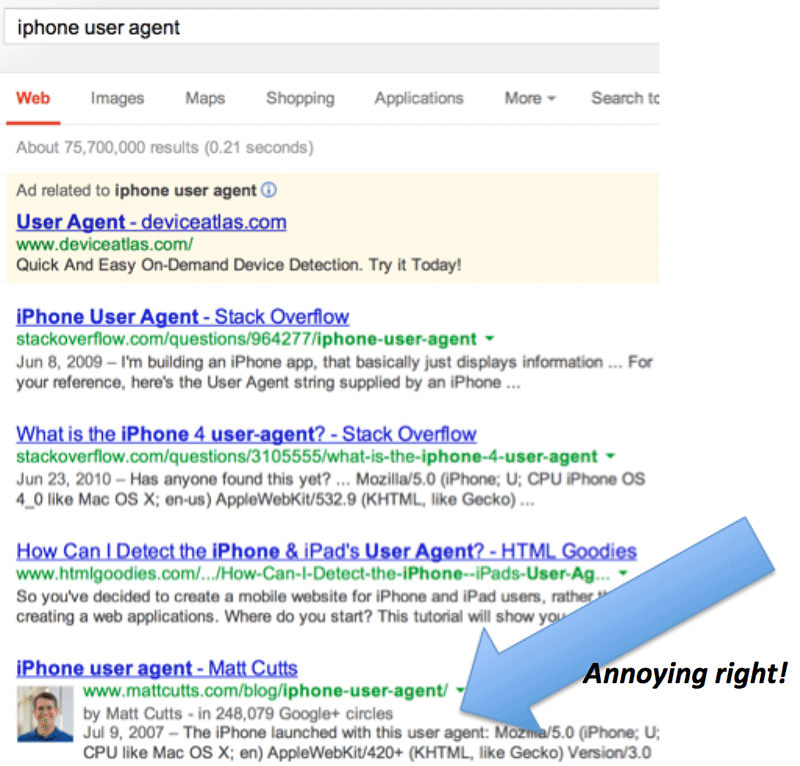
So after checking out his site, we can see that its powered by wordpress, therefore *could* have all sorts of vulnerabilities, but lets assume that the blog owner keeps everything up to date, and doesn’t have any rogue plugins installed.
Manufacturing Duplicate Content
Lets be clear, if someone copies your content, there is very little you can do.
Lets also be clear, Google is really bad at identifying the source of any piece of content.
BUT – it is YOUR RESPONSIBILITY to make sure you haven’t allowed a technical problem that might result in duplicate content issues on site.
There are two main ways of manufacturing on-site duplicate content, both have a major dependency:
(if this is not in place, negative SEO would not work)
** a page with a DIFFERENT URL containing the same content MUST NOT render an http 200 header **
You could just add a query string for instance: www.mattcutts.com/blog/iphone-user-agent/?variable=dupecontent that would serve the purpose of rendering the page again, with the same content, thus creating duplicate content.
UNLESS the target site has rel=canonical correctly implemented (which it does).
But thats not all we can do when screwing around with URL’s…
Wildcard Subdomains
Basically, a really bad idea, 99% of the time. You can see a site that allows wildcard subdomains by inserting a random character string before the FQD, lets take a look at what happens when you go to:
blahblah.martinmacdonald.net
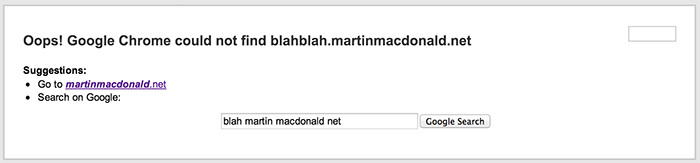
That is behaving EXACTLY as its meant to, it returns a straight 404 not found response code, but lets look at a similar page on MattCutts.com:
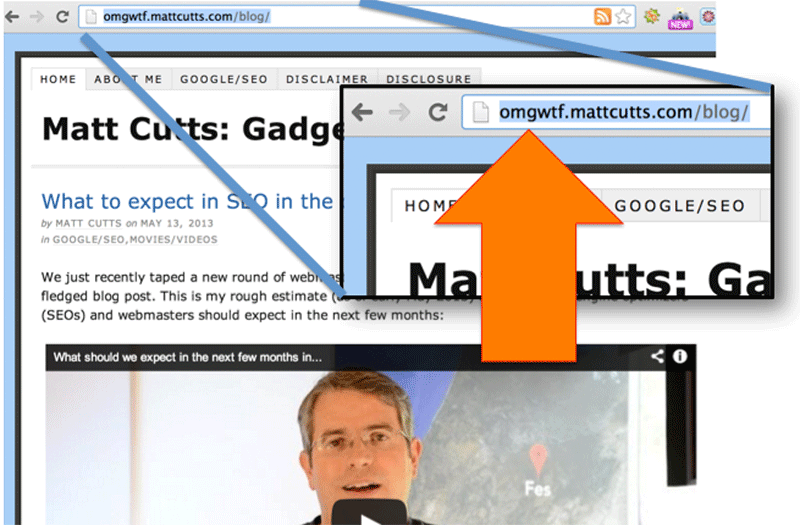
Using ANY subdomain apart from www.* results in a full duplicate copy of the Matt Cutts blog, each page returning a 200 http response. Pretty handy if you wanted to, for instance, de-index it for a specific keyword term. 😉
So lets pick on that iPhone post again. For google to see it, I need to link to it. Something like this would work: iPhone User Agent. Now google is going to see the page, and index it. Unless that Rel=Canonical is setup correctly again, so lets check:
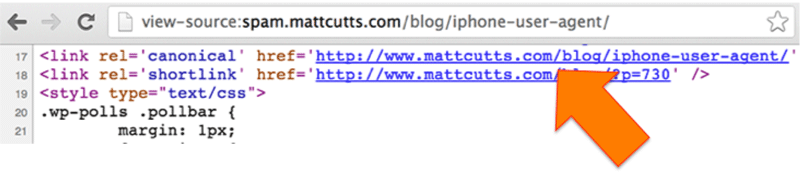
as you can see in the screenshot, that page is correctly canonicalised to the correct page, on the REAL subdomain.
DAMNIT. The blog is protected. Isn’t it?
Well, not quite. Knowing that the server is accepting wildcard subdomain requests, we know there is an SEO vulnerability – and this motivates us like nothing else to find a route through the protection, so lets fire up Screaming Frog!
First thing is to configure the spider to search for the inclusion (or omission) of a rel=canonical tag (handy guide available here from SEER) and find pages that DO NOT HAVE REL CANONICAL in the source code.
Surprisingly, this turned out a few URL’s, crucially the homepage and the /blog/ homepage are included in that list. So now we know we can screw with the rankings for those pages by creating on-domain duplicate content, and using searchmetrics we can pretty quickly work out what those pages rank for:
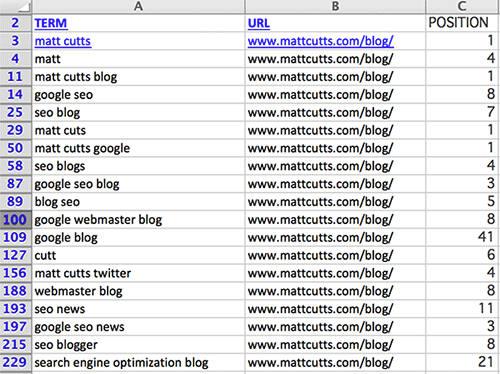
I particularly like the rankings: SEO Blog & webmaster blog so lets start with those, and simply put the links in this line of text should be enough to use the Panda algorithm update to confuse google into not ranking the site, by creating domain level duplicate content.
By linking to the duplicate page with exact match anchor text, we theoretically are sending google a signal that those pages are significant for the query as used in the anchor text, and by MattCutts.com serving the same page as it would do on the ‘www.’ subdomain its creating duplicate content.
Sweet!
So we’ve found a vulnerability, and taken advantage of it to hurt rankings on the target site, but what about that iphone user agent post?
Well: unfortunately, the above would really only work on pages where you can create duplicates without a canonical tag, and that post has one – so this will not directly impact that ranking. It will however negatively impact the site as a whole, and if it were replicated hundreds of thousands / millions of times, its likely to cause significant crawl equity and subsequent ranking problems to the main site.
Hey, I’d love to help test this:
If you would like to help out this negative SEO test, please just link to the following pages and anchor texts:
http://seo-blog.mattcutts.com/blog/ Anchor text: “SEO Blog”
http://webmaster-blog.mattcutts.com/blog/ Anchor text: “Webmaster Blog”
From any sites that you have direct access to. As with all negative SEO tests, I strongly recommend only doing this on domains that you can immediately remove the links from in future should the need arise.
Hey, I’m Matt Cutts and I’d like to prevent this:
Two ways: either correct the server config to disallow wildcard subdomains,
OR
make totally sure that every page on your site has the correct fully qualified URL within the rel canonical tag.
Footnote:
a quick way of finding which pages have been linked to externally, but do not carry a rel canonical (hence are indexed) is by doing this:
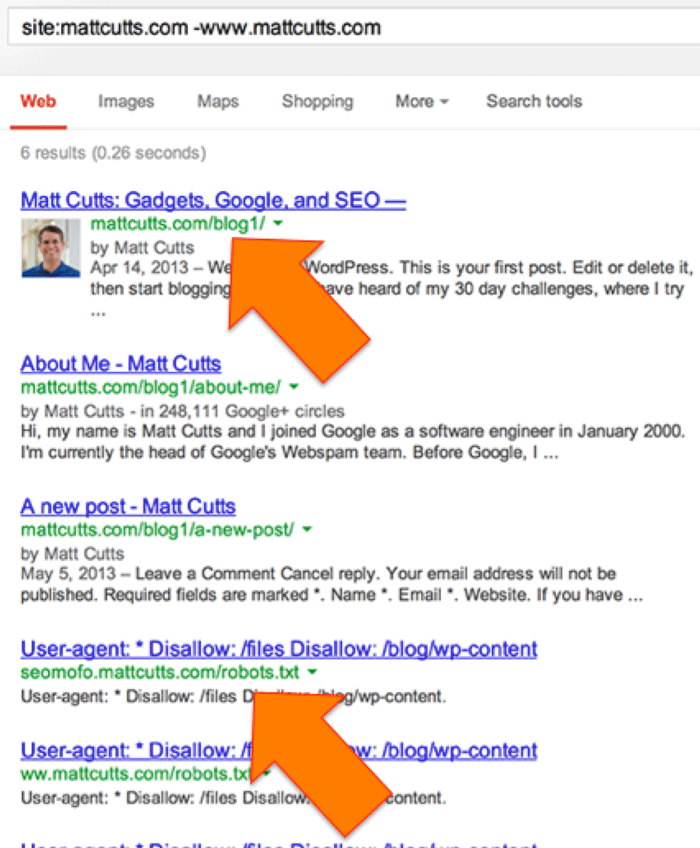
which reveals some other interesting stuff:
1) there is a duplicate installation of wordpress on mattcutts.com under the /blog1/ folder. My guess is that if you wanted to brute force a WP installation on that domain, choosing this one is probably a good idea.
2) the second orange arrow points out the subdomain seomofo.mattcutts.com so I assume that Darren Slatten has also noticed this vulnerability.
(angry)
UPDATE
@searchmartin From what I can see your site has been omitted from search results! pic.twitter.com/P2vVXf7Lhn
— Adam Mason (@AdamJamesMason) May 14, 2013
As if to prove my point, this very post (with several hundred tweets/plus ones etc.) is ALREADY being outranked by a near identical copy, which even links to my page: http://www. blackhatworld.com/ blackhat-seo/black-hat-seo /565146-negative-search-engine-optimization-vs-mattcutts-com.html (you will have to remove spaces to get the link to work).
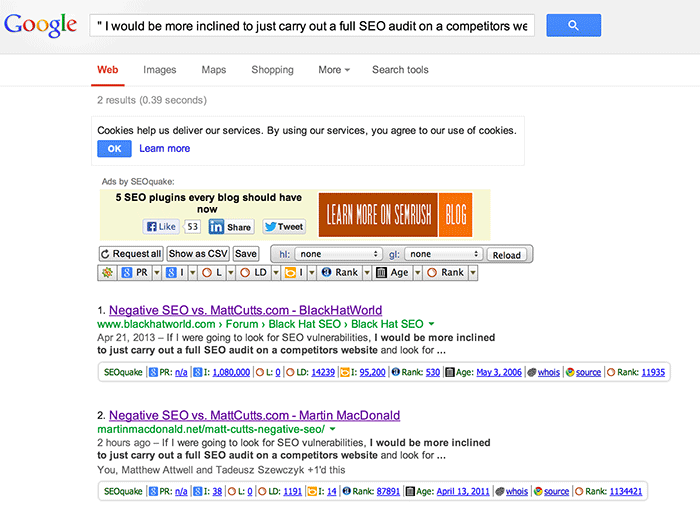
as you can see, the BHW thread already outranks me for my OWN CONTENT.
Let me just remind you that “my own content” has shitloads of social citations, probably quite a few links, and not to mention a LINK FROM THE COPIED ARTICLE AS WELL. It really shouldn’t be this hard Google.
(Happy)
Update
So less than 20 hours after posting the above, Matt appears to have taken the steps noted above and prevented wildcard subdomains from rendering on his personal domain: