Scraping Google for keyword rankings is a tricky business, they don’t want you to do it, and have gone as far as calling applications that do it “Black Hat”.
Scraping Google for keyword rankings is a tricky business, they don’t want you to do it, and have gone as far as calling applications that do it “Black Hat”.
Let’s not forget, they’ve also said which ones they perceive to be accurate, so lets ignore the Black Hat bit and build our own!
(sorry Google).
It would be interesting to hear other people’s opinions on this, so don’t forget to leave a comment below and let me know whether you think its black hat, whether you care, and if you’d like more of these posts (that Google may not appreciate!).
The first thing we need to prepare, is a large amount of keyword ranking data, everything we build from here on in will be based on this data:
What use is Keyword Data?
This is the beauty, there’s hundreds of uses for SERP data, from the most obvious – tracking your site performance, all the way up to building a complete index of the keywords you’re interested in to build interactive rank models, or find new business opportunity.
Over the years I’ve found dozens of ways to manipulate this data for quick and easy wins, many of which we’ll cover in future posts, but to get started the first thing you’re going to need is a reliable source of all the SERP data you can grab.
What do you mean by “All SERP Data”?
 Most tools only provide you with the rankings your site is in, not the rankings for everyone else across your keyword set.
Most tools only provide you with the rankings your site is in, not the rankings for everyone else across your keyword set.
This might seem like a level of data thats not relevant to you, after all, why should you care where other people rank?
Well, there’s plenty of application in being able to track other companies performance, not least being able to quickly see winners and losers during major google updates.
Imagine owning the data, relevant to your industry, that you wait a week to read in blog posts by SearchMetrics or SEMrush.
That’s potentially a major advantage, and I’m staggered more companies don’t take advantage of.
How can I get me some?
As with everything in life, there’s choices, but first lets recap the normal paths to keyword data:
1) Search Console / Google Webmaster Tools:
This gives you a couple of thousand keywords your site ranks for, that receive impressions.
The problems here are that you don’t get to decide which keywords are selected, you may have many more than are displayed, and if a keyword isn’t receiving impressions, you don’t get the data. You also only see your rank, not who ranks around you.
For the purposes we’re looking at today, essentially useless.
2) SaaS Rank Trackers (Software as a Subscription rank checkers, typically paid by way of a subscription)
This is the most commonly used source of keyword data today. Advantages are chiefly that you don’t need to spend time building scrapers, keeping them up to date (this is a bigger issue than most people realize), acquiring IP blocks to scrape with and so on.
Basically, SaaS rank trackers take all the hard work in SERP tracking, and provide you with just the data. If that’s what you’re looking for, then GetSTAT have a great reputation, Advanced Web Ranking is one of my long term go-to favorites, and plenty of other tools offer both keyword tracking and multifunctioned tool sets (Again, SearchMetrics or SEMrush are great examples of enterprise and SMB platforms).
Note: other SaaS tools are available, lots of them. These are just the ones I personally recommend.
 The drawback, to me at least, of SaaS services though is twofold: Firstly all of these services charge you for usage – which in itself is fine, but I often go on “fishing expeditions” where I might scrape hundreds of thousands of keywords results looking for potential evidence of algorithm updates. Scale that up over a month, and I might scrape 3 or 4 million keywords.
The drawback, to me at least, of SaaS services though is twofold: Firstly all of these services charge you for usage – which in itself is fine, but I often go on “fishing expeditions” where I might scrape hundreds of thousands of keywords results looking for potential evidence of algorithm updates. Scale that up over a month, and I might scrape 3 or 4 million keywords.
These tools can do this, but it could get expensive quickly – and often these scrapes don’t reveal anything.
Secondly, because you’re requesting a job be processed, there can be delays in getting back your data. This is of course true albeit to a lesser extent, of scraping results yourself, but at least then they are on your local machine, not at a remote server.
3) Locally Installed Rank Check Software:
This is where we’ll be concentrating for the rest of this post – and is my personal choice for obtaining large datasets of SERP data.
![]() Having a local rank tracking solution allows you to scrape results at no additional cost, regardless of how many keywords you choose to grab.
Having a local rank tracking solution allows you to scrape results at no additional cost, regardless of how many keywords you choose to grab.
The only limitations are how much data you can reliably scrape with your IP address, but this is mitigated with cheap VPN access allowing you to scale up almost infinitely.
It’s not going to be a “set and forget” solution though, if you want ultimate reliability then the SaaS option may be more appropriate, if like me however you don’t mind the occasional hassle then this is how I build indexes of the web.
Assuming you wish to use this in place of your SaaS tools, I strongly recommend you check daily whether its working correctly.
My current weapon of choice to scrape google is Link Assistant’s Rank Tracker:
Adapting Link Tracker to Export All Data
Unfortunately, Rank Tracker doesn’t perform all the steps necessary right out of the box, but the team over at Link Assistant have provided me with a hacked together custom report, which DOES do exactly what we are looking for!
Instructions:
1) Download and install Rank Tracker
2) Scrape your keyword set, its important to have a complete a picture as possible here (this will be covered in more detail later this week)
3) In Rank Tracker, simply choose “File>Export” and just click through with the default options enabled until you reach the “Preview / Code” screen (just press Next 4 times)
4) In the Code / Preview screen, select the Code entry area, and delete all its contents. Replace them with:
<[DEFINE name="dateFormat" value="exportData.createDateFormat('MM-dd-yyyy')"/]>
<[DEFINE name="keywords" value="exportData.keywords"/]>
<[DEFINE name="searchEngines" value="exportData.searchEngines"/]>
<[DEFINE name="index" value="0"/]>
<[DEFINE name="historyIndex" value="0"/]>
#,Keyword,<[FOR_EACH name="searchEngines" id="searchEngineType"]><[ECHO text="searchEngineType.getName()"/]> CheckDate,<[ECHO text="searchEngineType.getName()"/]> Position,<[ECHO text="searchEngineType.getName()"/]> URL,<[/FOR_EACH]>
<[FOR_EACH name="keywords" id="keyword"]>
<[DEFINE name="maxRecords" value="0"/]>
<[FOR_EACH name="searchEngines" id="searchEngineType"]>
<[DEFINE name="serpHistory" value="keyword.getSerpHistory(searchEngineType)"/]>
<[IF condition="serpHistory != null"]>
<[THEN]>
<[DEFINE name="serpHistoryMap" value="serpHistory.getHistoryRecordsMap()"/]>
<[DEFINE name="lastSerpHistoryEntry" value="serpHistoryMap.entrySet().iterator().next()"/]>
<[DEFINE name="date" value="lastSerpHistoryEntry.getKey()"/]>
<[DEFINE name="records" value="lastSerpHistoryEntry.getValue()"/]>
<[EXECUTE expression="maxRecords = Math.max(maxRecords, records.length)"/]>
<[/THEN]>
<[/IF]>
<[/FOR_EACH]>
<[FOR id="position" from="0" to="maxRecords"]><[ECHO text="index+1" formatType="CSV"/]>,<[ECHO text="keyword.query" suppressEncoding="true" formatType="CSV" formatedTextType="String"/]>,<[FOR_EACH name="searchEngines" id="searchEngineType"]><[DEFINE name="serpHistory" value="keyword.getSerpHistory(searchEngineType)"/]><[IF condition="serpHistory != null"]><[THEN]><[DEFINE name="serpHistoryMap" value="serpHistory.getHistoryRecordsMap()"/]><[DEFINE name="lastSerpHistoryEntry" value="serpHistoryMap.lastEntry()"/]><[DEFINE name="date" value="lastSerpHistoryEntry.getKey()"/]><[DEFINE name="records" value="java.util.Arrays.asList(lastSerpHistoryEntry.getValue())"/]><[IF condition="records.size() > positionCounter"]><[THEN]><[DEFINE name="record" value="records.get(positionCounter)"/]><[ECHO text="dateFormat.format(date)" suppressEncoding="true" formatType="CSV" formatedTextType="Date"/]>,<[ECHO text="positionCounter+1" formatType="CSV"/]>,<[DEFINE name="urls" value="record.getFoundUrls()"/]><[IF condition="urls.length > 0"]><[THEN]><[ECHO text="urls[0]" suppressEncoding="true" formatType="CSV" formatedTextType="String"/]><[/THEN]><[/IF]>,<[/THEN]><[ELSE]>,,,<[/ELSE]><[/IF]><[/THEN]><[ELSE]>,,,<[/ELSE]><[/IF]><[/FOR_EACH]>
<[EXECUTE expression="index++"/]>
<[/FOR]>
<[/FOR_EACH]>
5) Now when you hit Export, assuming you’ve followed all the instructions above, your export will look something like this:
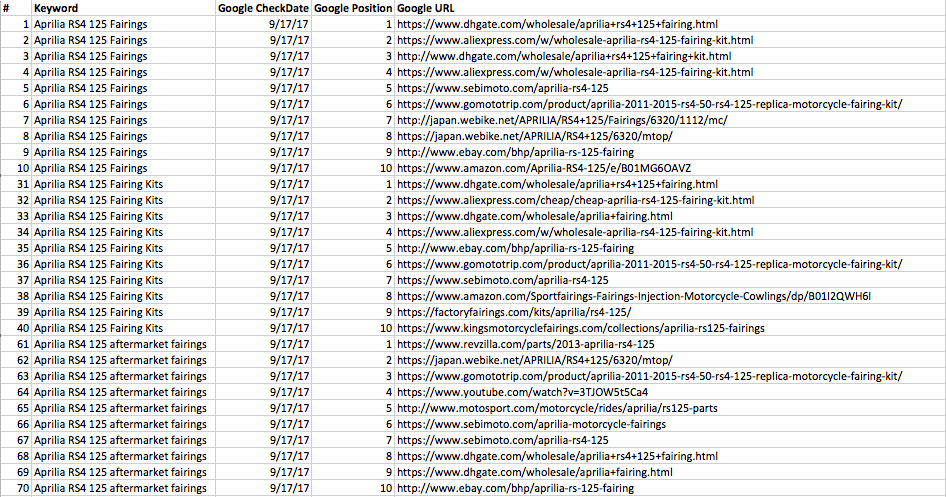
As you can see, what we have now is all the sites that rank in the top 10 positions for my first three keywords.
Each SERP position has a landing page, and from here we can start building out the rest of our dataset and start analyzing things like the specific ranking factors needed for our own industries!
Whats next?
Every day this week I’m publishing another post, with further ideas and instructions on how you can use this data to better inform your marketing strategy.
While every day we’ll be looking at a different use case, all of them will be based on this format of keyword data, so if you don’t already have a decent SERP datasource, go ahead and get yours built right now!